Web Scraping for Competitor Intelligence - 2026 Guide
Feb 17, 2026
Web Scraping
Competitor Intelligence
Market Research
Web Scraping
Competitor Intelligence
Market Research
As of January 2026, the business landscape has evolved beyond simple observation. For any enterprise aiming to maintain a competitive foothold, the ability to interpret market shifts before they fully manifest is no longer a luxury—it is a survival requirement. Competitive intelligence now serves as the central nervous system for modern business strategy, with approximately 78% of high-growth companies utilizing automated tools to secure a distinct market advantage. The transition from manual observation to automated data ingestion has been swift, leaving those who rely on outdated methods behind.
Web scraping for competitor intelligence and automated industry trend analysis has emerged as the primary catalyst for this transformation. By systematically extracting data from the digital footprints of rivals, organizations can move from reactive guessing to proactive execution. Recent data indicates that 65% of businesses reported a significant improvement in high-level decision-making processes immediately following the implementation of automated scraping protocols. This is not merely about tracking a competitor's public moves; it is about analyzing inventory levels, pricing elasticity, and customer sentiment in real-time.
Industry leaders such as Nike and Walmart have established the standard for this data-driven approach. By deploying sophisticated data extraction pipelines, these giants have achieved approximately 25% better market positioning compared to their less tech-forward counterparts. They are not just observing the surface; they are monitoring thousands of SKU changes and promotional shifts every hour. At Botomation, we see this pattern consistently across the B2B sector. We help clients implement 7 steps to automate competitor intelligence for B2B sales to ensure that when you stop guessing and start measuring, market dominance becomes a matter of engineering rather than luck.
Understanding Web Scraping for Competitive Intelligence
Web scraping serves as the foundational layer of any modern automated market research strategy. At its core, it involves the use of specialized scripts and bots to navigate websites, identify specific data points, and transform unstructured information into a usable, structured format. In previous years, market research often meant allocating significant human capital to manual data entry—a process riddled with human error. Modern companies are learning how AI agents replace manual data entry work to eliminate perpetually outdated information and high operational costs.
The "New Way," championed by Botomation, treats the entire internet as a structured database. By automating this process, we enable businesses to capture data at a scale and frequency that no human team could ever match. This involves more than just scraping a single page; it requires a deep understanding of web architecture and how data can be integrated into broader business intelligence platforms. When these systems are configured correctly, they feed directly into your CRM or internal dashboards, providing a continuous stream of insights that inform everything from product development to sales outreach.
What is Competitor Intelligence Through Web Data
Competitor intelligence in the digital age is the practice of gathering and analyzing publicly available information to gain a strategic edge. It is the process of turning raw web data—such as HTML tags, JSON responses, and JavaScript-rendered content—into actionable business logic. This data typically falls into three categories: pricing structures, product launch cycles, and customer sentiment. By monitoring these three pillars, a company can predict a competitor's next move with surprising accuracy.
Publicly available data is the most underutilized asset in many B2B organizations. Every time a competitor updates a job listing, modifies a line of code on their pricing page, or receives a new review on a third-party platform, they are signaling their strategy. Web scraping automates the collection of these signals. Instead of waiting for a quarterly report that is already three months old, utilizing automated daily market intelligence for sales teams allows your staff to receive alerts the moment a competitor adjusts their value proposition. This level of visibility is what separates market leaders from those who are constantly playing catch-up.
Legal Framework and Ethical Considerations
Navigating the legalities of web scraping in 2026 requires a sophisticated understanding of both international law and technical protocols. While scraping publicly available data is generally legal—as reaffirmed by landmark court cases between 2022 and 2024—it must be performed with respect for the host's infrastructure. The primary rule of ethical scraping is adhering to the robots.txt file, which acts as a guide for what a website allows bots to access. Ignoring these directives can lead to IP blocking and potential legal friction.
Recent legal developments in late 2026 have placed a greater emphasis on data privacy and server load management. It is no longer enough to simply "get the data"; you must do so without disrupting the competitor's site performance. This involves implementing strict rate limits and using sophisticated proxy rotation to ensure requests mimic natural human traffic. At Botomation, we prioritize compliant data collection practices to ensure our clients gain intelligence without incurring unnecessary risk. Staying within the bounds of terms of service while extracting high-value data is an art form that requires constant monitoring of the evolving legal landscape.
Expert Insight: "The goal of competitive intelligence is not to disrupt your competitor's operations, but to understand them. High-frequency scraping without proper rate limiting is not just unethical; it's a technical failure that leads to detection and data loss."
Web scraping for competitor intelligence
To execute web scraping for competitor intelligence effectively, one must move beyond basic scripts and into the realm of enterprise-grade infrastructure. The core techniques involve identifying the target's "data fingerprints"—the specific HTML classes or API endpoints where their most valuable information resides. This is followed by the deployment of a scraping architecture that can handle the complexities of the modern web, including single-page applications (SPAs) and sites that rely heavily on client-side rendering.
Setting up an automated monitoring system requires a blend of software engineering and strategic thinking. You are not just looking for a snapshot in time; you are building a time-series dataset that shows how a competitor's strategy evolves. This might involve daily scrapes of their "Features" page to detect subtle shifts in product positioning or hourly checks on their stock levels. Real-world success in this area comes from the ability to clean and normalize this data so it can be compared directly against your own internal metrics.
Essential Tools for Competitor Data Extraction
Choosing the right toolset is the first hurdle in building a scraping engine. To narrow down your options, you can review our guide on the best competitor analysis tools for 2026. For many developers, Python-based libraries like Scrapy and Beautiful Soup remains the gold standard due to their flexibility and massive community support. Selenium and Playwright are also frequently utilized, especially when dealing with sites that require human-like interaction or have complex JavaScript elements. These tools allow a script to click buttons, fill out forms, and wait for elements to load, just as a real user would.
However, the software is only half of the equation. Cloud-based scraping services like Oxylabs or ScrapingBee have become essential for handling the infrastructure side of things. These services provide the proxy networks and browser environments necessary to bypass sophisticated anti-bot systems. By utilizing API-based solutions for structured data extraction, companies can bypass the "Old Way" of managing their own server farms. This allows our experts to focus on the data logic rather than the maintenance of proxy lists and headless browser instances.
Building Custom Scraping Solutions
When a generic tool is insufficient, building a custom solution is the only way to ensure data integrity. Custom scrapers are typically written in Python or JavaScript (Node.js) and are designed to handle the specific quirks of a competitor's website. This includes managing session cookies, handling redirects, and navigating through complex login portals. The use of headless browsers, which run a browser environment without a graphical user interface, allows these scripts to interact with modern websites at high speed while remaining undetected.
Data storage is another critical component of a custom solution. Once the data is extracted, it must be stored in a way that facilitates analysis. We often implement a combination of SQL databases for structured pricing data and NoSQL databases for more fluid, unstructured information like product descriptions or customer reviews. Monitoring and alert systems are then built on top of these databases. For instance, if a competitor’s price drops by more than 10%, an automated alert is sent directly to the client's Slack or email, allowing for an immediate strategic response.
Pricing Data Extraction Strategies
Pricing is perhaps the most volatile and impactful data point you can track. In sectors like e-commerce or SaaS, prices can change multiple times a day based on demand, inventory, or competitor movements. Advanced techniques to track competitor pricing automatically involve more than just looking at the primary price tag. It requires extracting the "Total Cost of Ownership," which includes shipping costs, taxes, and any hidden fees that might be buried in the checkout process.
Once this data is collected, it can be used to fuel dynamic pricing models. This is where the true power of automation lies. Instead of a manager manually approving every price change, a system can be programmed to automatically adjust your prices within a set range based on the scraped data. This ensures you remain competitive without sacrificing margins. A classic example of this is how Zara uses pricing intelligence. By monitoring over 20 global competitors hourly, they can adjust their market positioning in real-time, ensuring they capture the maximum possible value from every trend.
E-commerce Price Monitoring Techniques
Extracting pricing data from major e-commerce platforms requires navigating a minefield of anti-bot measures. Retailers like Amazon or eBay use sophisticated behavioral analysis to identify and block scrapers. To counter this, we use techniques like TLS fingerprinting, which makes our bot's network signature look identical to a standard Chrome or Safari browser. We also implement "human-like" browsing patterns, such as varying the time between clicks and moving the mouse cursor in non-linear paths.
The choice between real-time and batch processing is also a key strategic decision. Real-time processing is necessary for high-frequency trading or lightning deals, where every second counts. However, for most B2B applications, batch processing—where data is collected and analyzed at set intervals—is more cost-effective and provides a clearer view of long-term trends. Integrating this data with your internal inventory management system allows for a "closed-loop" strategy where your stock levels and pricing are always in perfect harmony with the market.
Dynamic Pricing Algorithm Development
Developing a dynamic pricing algorithm is a multi-step process that combines data science with market psychology. We start by building machine learning models that analyze historical pricing data alongside external factors like seasonal trends and competitor stock-outs. The algorithm then calculates the "Optimal Price Point" that maximizes either volume or profit, depending on the current business goal. This is not a "set it and forget it" system; it requires constant A/B testing to ensure the logic holds up under changing market conditions.
The ROI of these implementations is often staggering. When a company can move its price by just 1% in the right direction, it can lead to an 11% increase in operating profit on average. By automating this through web scraping, you remove emotional bias and the delay of manual decision-making. We help our clients calculate these numbers step-by-step, showing how the initial investment in a custom Botomation pipeline pays for itself within the first few months of operation.
| Feature | Manual Research (The Old Way) | Automated Scraping (The New Way) |
|---|---|---|
| **Data Frequency** | Weekly or Monthly | Hourly or Real-time |
| **Accuracy** | High risk of human error | 99.9% data integrity |
| **Cost Efficiency** | High labor costs ($50k+/yr) | Low operational overhead |
| **Scalability** | Limited by team size | Unlimited; monitor 10k+ sites |
| **Actionability** | Stale data leads to late moves | Instant alerts for immediate action |
Automated Market Research Implementation
Setting up an end-to-end market research automation system is what transforms a company from a participant into a market leader. This involves creating a seamless pipeline where data flows from the web, through a cleaning process, and into a visualization tool that the executive team can actually use. The goal is to reduce the "Time to Insight"—the duration between a market event happening and your team knowing about it.
Performance metrics and optimization are the final pieces of the puzzle. You need to know if your scrapers are failing, if the data quality is dropping, or if a competitor has completely redesigned their site, breaking your extraction logic. At Botomation, we build these monitoring systems directly into our service, ensuring that the flow of intelligence never stops. We do not just provide a tool; we provide a managed intelligence stream that evolves as the market does.
Data Pipeline Architecture

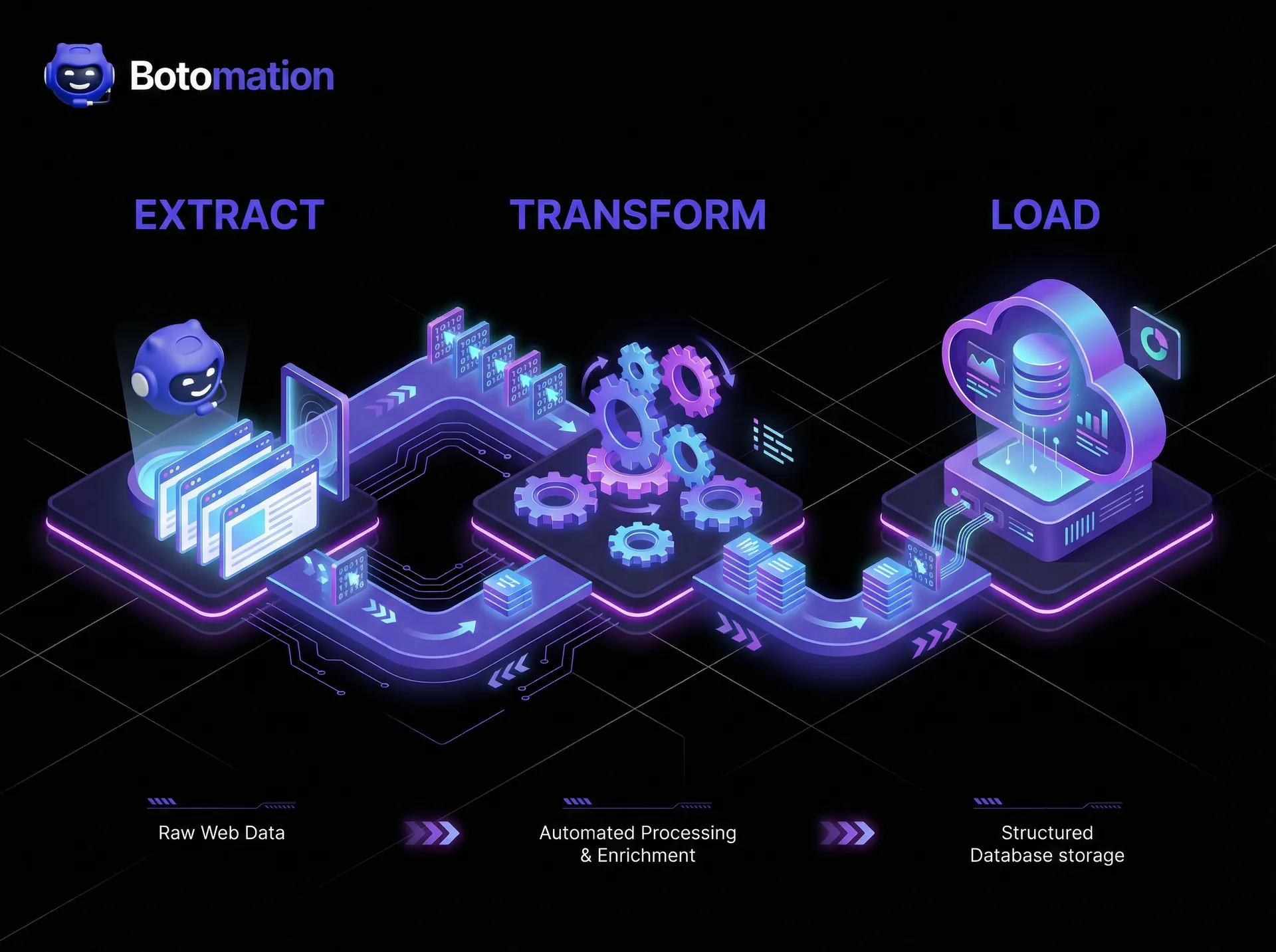
The architecture of a data pipeline is often referred to as an ETL process: Extract, Transform, Load. First, we extract the raw HTML or JSON from the target sites. Next, we transform that "messy" data into a clean, structured format. This might involve stripping out HTML tags, converting currencies, or normalizing product names so they match your internal catalog. Finally, we load that data into a data warehouse like BigQuery or Snowflake, where it can be queried by your analysts.
Scalability is a major consideration here. A pipeline that works for 10 websites might break when you try to scale to 1,000. This is why we use containerization (like Docker) and orchestration (like Kubernetes) to manage our scraping agents. This allows us to spin up more "workers" as data requirements grow, ensuring that your market research capabilities are never throttled by technical limitations. We also implement rigorous data validation checks at every stage to ensure that one bad scrape does not poison your entire dataset.
Market Intelligence Dashboard Design
A dashboard is only as good as the decisions it enables. When we design market intelligence dashboards, we focus on key performance indicators (KPIs) that matter to the C-suite. This includes "Share of Voice," "Competitor Price Index," and "Sentiment Velocity." We avoid cluttered screens and instead focus on visualizing trends. For example, a line graph showing a competitor's average price over time is much more valuable than a table of 500 individual prices.
Integration with existing business intelligence tools like Tableau, Power BI, or even custom internal portals is essential. Your team should not have to log into a new platform to see the data. By pushing the scraped insights directly into the tools they already use, you increase adoption and ensure the intelligence is actually acted upon. Alert systems are the "active" part of the dashboard; they push notifications to the right people when a significant market shift is detected, turning the dashboard from a passive display into an active strategic tool.
Key Statistic Box:
- 85% reduction in manual research time for companies using automated pipelines.
- 23% average increase in market share for early adopters of pricing automation.
- $56,250 – The total annual cost of a junior researcher ($45,000 base + $11,250 benefits), which can be replaced by a more efficient automated system.
Real-World Success Stories and ROI
The theoretical benefits of web scraping are compelling, but the real-world results are where the value becomes undeniable. We have seen companies across various sectors completely redefine their market position by simply having better data than their rivals. In the financial services sector, for instance, the ability to scrape and analyze public filings, news sentiment, and alternative data sources has allowed firms to reduce their market research time by a staggering 85%.
The technology sector provides another excellent example. In a field where product features and pricing models change almost weekly, a major software company utilized our custom scraping solutions to monitor 45 different competitors. By identifying a gap in a competitor's pricing tier through automated analysis, they were able to launch a targeted campaign that resulted in a 45% improvement in their competitive win rate. These are not just incremental gains; they are transformative shifts in business performance.
Retail Industry Transformation
One of the most impressive case studies involves a large retail giant that was struggling to maintain its market share against nimble e-commerce startups. By implementing a high-frequency pricing and inventory scraper, they were able to increase their market share from 18% to 23% in just 14 months. The technical challenge was immense: they needed to monitor over 50,000 SKUs across 20 different websites every four hours.
The implementation timeline was aggressive, taking only eight weeks from the initial consultation to a fully operational pipeline. This required a dedicated team of data engineers and analysts to ensure the data was not only accurate but also integrated into the client's automated repricing engine. The result was a 12% increase in gross margin on their top-performing categories, simply because they were no longer operating without market visibility during promotional periods.
Financial Services Market Intelligence
In the financial services world, data is the only currency that truly matters. A mid-sized investment firm partnered with us to automate their collection of "alternative data"—specifically, scraping job boards to track headcount growth at private tech companies and monitoring retail foot traffic data through public web portals. This automated analysis reduced their research time from weeks to hours, allowing them to make investment decisions faster than their larger competitors.
Regulatory compliance was a major hurdle in this project. We ensured that all data collection was strictly limited to publicly available information and that no protected data was ever touched. By building a transparent and auditable scraping trail, we helped the firm maintain compliance while still gaining a massive informational edge. The client reported a significant increase in satisfaction among their own investors, who valued the data-driven approach to market intelligence.
Technical Challenges and Solutions
While the benefits are clear, web scraping is not without its hurdles. The web is a chaotic environment, and websites are constantly changing. A scraper that works perfectly today might break tomorrow because a developer changed a single div tag. Managing large-scale extraction projects requires a robust "self-healing" architecture that can detect these changes and alert the engineering team immediately.
Anti-bot detection is the other major challenge. As scraping becomes more common, websites are investing more in "bot management" solutions like Cloudflare or Akamai. Bypassing these requires a constant game of cat-and-mouse, utilizing advanced techniques that go far beyond simple IP rotation. At Botomation, we stay ahead of this curve by constantly updating our browser fingerprinting and proxy management strategies.
Anti-Bot Bypass Techniques
The most sophisticated anti-bot systems look at more than just your IP address. They examine your "browser fingerprint," which includes your screen resolution, installed fonts, and even the way your browser renders specific graphics. To bypass this, we use headless browser management tools that can spoof these fingerprints perfectly. We also cycle through thousands of residential proxies, which make our traffic appear to come from real home internet connections rather than a data center.
Timing is another crucial factor. If a bot visits the same 500 pages in the exact same order every hour, it is easy to detect. We implement "jitter" and randomized navigation paths to simulate natural human browsing behavior. We also use CAPTCHA-solving services that utilize a mix of AI and human workers to solve challenges when they do appear. This multi-layered approach ensures that our data collection remains uninterrupted, even against the most aggressive defenses.
Data Quality Assurance
Scraped data is often "noisy." It can contain HTML artifacts, inconsistent formatting, or missing values. To ensure data quality, we implement a series of automated validation checks. For example, if a price scraper suddenly reports a price of $0.00 for a product that usually costs $500.00, the system flags this as a potential error and prevents it from entering the main database. This "sanity checking" is vital for maintaining the trust of the end-users.
Cross-referencing data from multiple sources is another way we ensure accuracy. If three different websites report the same price for a competitor's product, we can be highly confident in that data point. If there is a discrepancy, our system can trigger a deeper analysis to determine the most likely truth. By treating data quality as a first-class engineering problem, we ensure that the intelligence we provide is not just fast, but also flawlessly accurate.
How to Set Up Your First Competitor Intelligence Scraper
If you are looking to move from manual research to automation, follow this basic framework to get started. While this is a simplified version of the enterprise solutions we provide at Botomation, it provides a solid foundation for understanding the process.
Step 1: Identify Your Targets and Data Points
Begin by listing the top 5 competitors you need to monitor. For each one, identify exactly which pages hold the most value (e.g., the /pricing page or the /blog for content trends). List the specific data points you need: product name, current price, stock status, and any discount labels.
Step 2: Inspect the Site Structure
Open your competitor's website in a browser, right-click on the data you want, and select "Inspect." Look for unique IDs or Classes in the HTML. For example, a price might be contained in a <span class=\"product-price\">. These are the "selectors" your scraper will use to find the information.
Step 3: Choose Your Environment
For a beginner, Python with the Requests and BeautifulSoup libraries is the easiest way to start. If the site uses a lot of JavaScript, you will need Playwright. Set up a local development environment and write a script that fetches the page and prints the specific selectors you identified in Step 2.
Step 4: Implement Basic Proxy Rotation
Do not scrape from your own IP address. Even a simple service like a rotating proxy provider will help you avoid getting blocked during the testing phase. Ensure you are respecting the site's robots.txt and not hitting their servers too hard.
Step 5: Schedule and Store
Once your script works, use a "cron job" or a cloud scheduler to run it at regular intervals (e.g., every morning at 8:00 AM). Direct the output into a CSV file or a simple Google Sheet. This will give you your first time-series dataset of competitor movements.
Frequently Asked Questions
Is web scraping legal for competitor intelligence?
Yes, scraping publicly available data is generally legal in most jurisdictions, including the US and EU. However, it must be done without violating the Computer Fraud and Abuse Act (CFAA) or bypassing password-protected portals. It is also essential to avoid causing technical harm to the target website through excessive traffic.
How often should I scrape my competitors?
The frequency depends on your industry. E-commerce companies often scrape hourly to keep up with dynamic pricing. In contrast, B2B service providers might only need to scrape weekly or monthly to track major feature updates or blog posts. Our team at Botomation helps you determine the optimal frequency to balance data freshness with operational costs.
Can websites block my scraping efforts?
Yes, many websites use anti-bot technology to prevent scraping. This can range from simple IP blocking to complex behavioral analysis. Bypassing these blocks requires sophisticated techniques like proxy rotation, browser fingerprinting, and human-like interaction patterns. This is why many companies choose to partner with an agency like Botomation rather than maintaining their own scrapers.
What is the difference between web scraping and web crawling?
While the terms are often used interchangeably, they differ slightly. Web crawling is the process of indexing an entire website (like Google does) to understand its structure. Web scraping is the targeted extraction of specific data points from those pages. For competitor intelligence, scraping is the primary tool used.
The competitive landscape of 2026 does not favor the slow or the uninformed. As we have explored, web scraping for competitor intelligence is the most effective way to gain a real-time, data-driven understanding of your market. The transition from manual research to automated, high-integrity data pipelines is the single biggest advantage a growth-focused company can implement today. By capturing pricing shifts, product changes, and market trends as they happen, you empower your sales and marketing teams to act with precision.
Success in this field requires more than just a script; it requires a strategic partner who understands the technical, legal, and business nuances of data extraction. At Botomation, we specialize in building these custom intelligence engines for B2B sales teams and agencies who are tired of manual research and stale lead lists. We do not just give you data; we give you a competitive edge that works while you sleep.
Ready to automate your growth? Stop losing money to faster competitors and start making data-driven decisions today. Book a call below to see how our team can build your custom market intelligence engine.
As of January 2026, the business landscape has evolved beyond simple observation. For any enterprise aiming to maintain a competitive foothold, the ability to interpret market shifts before they fully manifest is no longer a luxury—it is a survival requirement. Competitive intelligence now serves as the central nervous system for modern business strategy, with approximately 78% of high-growth companies utilizing automated tools to secure a distinct market advantage. The transition from manual observation to automated data ingestion has been swift, leaving those who rely on outdated methods behind.
Web scraping for competitor intelligence and automated industry trend analysis has emerged as the primary catalyst for this transformation. By systematically extracting data from the digital footprints of rivals, organizations can move from reactive guessing to proactive execution. Recent data indicates that 65% of businesses reported a significant improvement in high-level decision-making processes immediately following the implementation of automated scraping protocols. This is not merely about tracking a competitor's public moves; it is about analyzing inventory levels, pricing elasticity, and customer sentiment in real-time.
Industry leaders such as Nike and Walmart have established the standard for this data-driven approach. By deploying sophisticated data extraction pipelines, these giants have achieved approximately 25% better market positioning compared to their less tech-forward counterparts. They are not just observing the surface; they are monitoring thousands of SKU changes and promotional shifts every hour. At Botomation, we see this pattern consistently across the B2B sector. We help clients implement 7 steps to automate competitor intelligence for B2B sales to ensure that when you stop guessing and start measuring, market dominance becomes a matter of engineering rather than luck.
Understanding Web Scraping for Competitive Intelligence
Web scraping serves as the foundational layer of any modern automated market research strategy. At its core, it involves the use of specialized scripts and bots to navigate websites, identify specific data points, and transform unstructured information into a usable, structured format. In previous years, market research often meant allocating significant human capital to manual data entry—a process riddled with human error. Modern companies are learning how AI agents replace manual data entry work to eliminate perpetually outdated information and high operational costs.
The "New Way," championed by Botomation, treats the entire internet as a structured database. By automating this process, we enable businesses to capture data at a scale and frequency that no human team could ever match. This involves more than just scraping a single page; it requires a deep understanding of web architecture and how data can be integrated into broader business intelligence platforms. When these systems are configured correctly, they feed directly into your CRM or internal dashboards, providing a continuous stream of insights that inform everything from product development to sales outreach.
What is Competitor Intelligence Through Web Data
Competitor intelligence in the digital age is the practice of gathering and analyzing publicly available information to gain a strategic edge. It is the process of turning raw web data—such as HTML tags, JSON responses, and JavaScript-rendered content—into actionable business logic. This data typically falls into three categories: pricing structures, product launch cycles, and customer sentiment. By monitoring these three pillars, a company can predict a competitor's next move with surprising accuracy.
Publicly available data is the most underutilized asset in many B2B organizations. Every time a competitor updates a job listing, modifies a line of code on their pricing page, or receives a new review on a third-party platform, they are signaling their strategy. Web scraping automates the collection of these signals. Instead of waiting for a quarterly report that is already three months old, utilizing automated daily market intelligence for sales teams allows your staff to receive alerts the moment a competitor adjusts their value proposition. This level of visibility is what separates market leaders from those who are constantly playing catch-up.
Legal Framework and Ethical Considerations
Navigating the legalities of web scraping in 2026 requires a sophisticated understanding of both international law and technical protocols. While scraping publicly available data is generally legal—as reaffirmed by landmark court cases between 2022 and 2024—it must be performed with respect for the host's infrastructure. The primary rule of ethical scraping is adhering to the robots.txt file, which acts as a guide for what a website allows bots to access. Ignoring these directives can lead to IP blocking and potential legal friction.
Recent legal developments in late 2026 have placed a greater emphasis on data privacy and server load management. It is no longer enough to simply "get the data"; you must do so without disrupting the competitor's site performance. This involves implementing strict rate limits and using sophisticated proxy rotation to ensure requests mimic natural human traffic. At Botomation, we prioritize compliant data collection practices to ensure our clients gain intelligence without incurring unnecessary risk. Staying within the bounds of terms of service while extracting high-value data is an art form that requires constant monitoring of the evolving legal landscape.
Expert Insight: "The goal of competitive intelligence is not to disrupt your competitor's operations, but to understand them. High-frequency scraping without proper rate limiting is not just unethical; it's a technical failure that leads to detection and data loss."
Web scraping for competitor intelligence
To execute web scraping for competitor intelligence effectively, one must move beyond basic scripts and into the realm of enterprise-grade infrastructure. The core techniques involve identifying the target's "data fingerprints"—the specific HTML classes or API endpoints where their most valuable information resides. This is followed by the deployment of a scraping architecture that can handle the complexities of the modern web, including single-page applications (SPAs) and sites that rely heavily on client-side rendering.
Setting up an automated monitoring system requires a blend of software engineering and strategic thinking. You are not just looking for a snapshot in time; you are building a time-series dataset that shows how a competitor's strategy evolves. This might involve daily scrapes of their "Features" page to detect subtle shifts in product positioning or hourly checks on their stock levels. Real-world success in this area comes from the ability to clean and normalize this data so it can be compared directly against your own internal metrics.
Essential Tools for Competitor Data Extraction
Choosing the right toolset is the first hurdle in building a scraping engine. To narrow down your options, you can review our guide on the best competitor analysis tools for 2026. For many developers, Python-based libraries like Scrapy and Beautiful Soup remains the gold standard due to their flexibility and massive community support. Selenium and Playwright are also frequently utilized, especially when dealing with sites that require human-like interaction or have complex JavaScript elements. These tools allow a script to click buttons, fill out forms, and wait for elements to load, just as a real user would.
However, the software is only half of the equation. Cloud-based scraping services like Oxylabs or ScrapingBee have become essential for handling the infrastructure side of things. These services provide the proxy networks and browser environments necessary to bypass sophisticated anti-bot systems. By utilizing API-based solutions for structured data extraction, companies can bypass the "Old Way" of managing their own server farms. This allows our experts to focus on the data logic rather than the maintenance of proxy lists and headless browser instances.
Building Custom Scraping Solutions
When a generic tool is insufficient, building a custom solution is the only way to ensure data integrity. Custom scrapers are typically written in Python or JavaScript (Node.js) and are designed to handle the specific quirks of a competitor's website. This includes managing session cookies, handling redirects, and navigating through complex login portals. The use of headless browsers, which run a browser environment without a graphical user interface, allows these scripts to interact with modern websites at high speed while remaining undetected.
Data storage is another critical component of a custom solution. Once the data is extracted, it must be stored in a way that facilitates analysis. We often implement a combination of SQL databases for structured pricing data and NoSQL databases for more fluid, unstructured information like product descriptions or customer reviews. Monitoring and alert systems are then built on top of these databases. For instance, if a competitor’s price drops by more than 10%, an automated alert is sent directly to the client's Slack or email, allowing for an immediate strategic response.
Pricing Data Extraction Strategies
Pricing is perhaps the most volatile and impactful data point you can track. In sectors like e-commerce or SaaS, prices can change multiple times a day based on demand, inventory, or competitor movements. Advanced techniques to track competitor pricing automatically involve more than just looking at the primary price tag. It requires extracting the "Total Cost of Ownership," which includes shipping costs, taxes, and any hidden fees that might be buried in the checkout process.
Once this data is collected, it can be used to fuel dynamic pricing models. This is where the true power of automation lies. Instead of a manager manually approving every price change, a system can be programmed to automatically adjust your prices within a set range based on the scraped data. This ensures you remain competitive without sacrificing margins. A classic example of this is how Zara uses pricing intelligence. By monitoring over 20 global competitors hourly, they can adjust their market positioning in real-time, ensuring they capture the maximum possible value from every trend.
E-commerce Price Monitoring Techniques
Extracting pricing data from major e-commerce platforms requires navigating a minefield of anti-bot measures. Retailers like Amazon or eBay use sophisticated behavioral analysis to identify and block scrapers. To counter this, we use techniques like TLS fingerprinting, which makes our bot's network signature look identical to a standard Chrome or Safari browser. We also implement "human-like" browsing patterns, such as varying the time between clicks and moving the mouse cursor in non-linear paths.
The choice between real-time and batch processing is also a key strategic decision. Real-time processing is necessary for high-frequency trading or lightning deals, where every second counts. However, for most B2B applications, batch processing—where data is collected and analyzed at set intervals—is more cost-effective and provides a clearer view of long-term trends. Integrating this data with your internal inventory management system allows for a "closed-loop" strategy where your stock levels and pricing are always in perfect harmony with the market.
Dynamic Pricing Algorithm Development
Developing a dynamic pricing algorithm is a multi-step process that combines data science with market psychology. We start by building machine learning models that analyze historical pricing data alongside external factors like seasonal trends and competitor stock-outs. The algorithm then calculates the "Optimal Price Point" that maximizes either volume or profit, depending on the current business goal. This is not a "set it and forget it" system; it requires constant A/B testing to ensure the logic holds up under changing market conditions.
The ROI of these implementations is often staggering. When a company can move its price by just 1% in the right direction, it can lead to an 11% increase in operating profit on average. By automating this through web scraping, you remove emotional bias and the delay of manual decision-making. We help our clients calculate these numbers step-by-step, showing how the initial investment in a custom Botomation pipeline pays for itself within the first few months of operation.
| Feature | Manual Research (The Old Way) | Automated Scraping (The New Way) |
|---|---|---|
| **Data Frequency** | Weekly or Monthly | Hourly or Real-time |
| **Accuracy** | High risk of human error | 99.9% data integrity |
| **Cost Efficiency** | High labor costs ($50k+/yr) | Low operational overhead |
| **Scalability** | Limited by team size | Unlimited; monitor 10k+ sites |
| **Actionability** | Stale data leads to late moves | Instant alerts for immediate action |
Automated Market Research Implementation
Setting up an end-to-end market research automation system is what transforms a company from a participant into a market leader. This involves creating a seamless pipeline where data flows from the web, through a cleaning process, and into a visualization tool that the executive team can actually use. The goal is to reduce the "Time to Insight"—the duration between a market event happening and your team knowing about it.
Performance metrics and optimization are the final pieces of the puzzle. You need to know if your scrapers are failing, if the data quality is dropping, or if a competitor has completely redesigned their site, breaking your extraction logic. At Botomation, we build these monitoring systems directly into our service, ensuring that the flow of intelligence never stops. We do not just provide a tool; we provide a managed intelligence stream that evolves as the market does.
Data Pipeline Architecture
The architecture of a data pipeline is often referred to as an ETL process: Extract, Transform, Load. First, we extract the raw HTML or JSON from the target sites. Next, we transform that "messy" data into a clean, structured format. This might involve stripping out HTML tags, converting currencies, or normalizing product names so they match your internal catalog. Finally, we load that data into a data warehouse like BigQuery or Snowflake, where it can be queried by your analysts.
Scalability is a major consideration here. A pipeline that works for 10 websites might break when you try to scale to 1,000. This is why we use containerization (like Docker) and orchestration (like Kubernetes) to manage our scraping agents. This allows us to spin up more "workers" as data requirements grow, ensuring that your market research capabilities are never throttled by technical limitations. We also implement rigorous data validation checks at every stage to ensure that one bad scrape does not poison your entire dataset.
Market Intelligence Dashboard Design
A dashboard is only as good as the decisions it enables. When we design market intelligence dashboards, we focus on key performance indicators (KPIs) that matter to the C-suite. This includes "Share of Voice," "Competitor Price Index," and "Sentiment Velocity." We avoid cluttered screens and instead focus on visualizing trends. For example, a line graph showing a competitor's average price over time is much more valuable than a table of 500 individual prices.
Integration with existing business intelligence tools like Tableau, Power BI, or even custom internal portals is essential. Your team should not have to log into a new platform to see the data. By pushing the scraped insights directly into the tools they already use, you increase adoption and ensure the intelligence is actually acted upon. Alert systems are the "active" part of the dashboard; they push notifications to the right people when a significant market shift is detected, turning the dashboard from a passive display into an active strategic tool.
Key Statistic Box:
- 85% reduction in manual research time for companies using automated pipelines.
- 23% average increase in market share for early adopters of pricing automation.
- $56,250 – The total annual cost of a junior researcher ($45,000 base + $11,250 benefits), which can be replaced by a more efficient automated system.
Real-World Success Stories and ROI
The theoretical benefits of web scraping are compelling, but the real-world results are where the value becomes undeniable. We have seen companies across various sectors completely redefine their market position by simply having better data than their rivals. In the financial services sector, for instance, the ability to scrape and analyze public filings, news sentiment, and alternative data sources has allowed firms to reduce their market research time by a staggering 85%.
The technology sector provides another excellent example. In a field where product features and pricing models change almost weekly, a major software company utilized our custom scraping solutions to monitor 45 different competitors. By identifying a gap in a competitor's pricing tier through automated analysis, they were able to launch a targeted campaign that resulted in a 45% improvement in their competitive win rate. These are not just incremental gains; they are transformative shifts in business performance.
Retail Industry Transformation
One of the most impressive case studies involves a large retail giant that was struggling to maintain its market share against nimble e-commerce startups. By implementing a high-frequency pricing and inventory scraper, they were able to increase their market share from 18% to 23% in just 14 months. The technical challenge was immense: they needed to monitor over 50,000 SKUs across 20 different websites every four hours.
The implementation timeline was aggressive, taking only eight weeks from the initial consultation to a fully operational pipeline. This required a dedicated team of data engineers and analysts to ensure the data was not only accurate but also integrated into the client's automated repricing engine. The result was a 12% increase in gross margin on their top-performing categories, simply because they were no longer operating without market visibility during promotional periods.
Financial Services Market Intelligence
In the financial services world, data is the only currency that truly matters. A mid-sized investment firm partnered with us to automate their collection of "alternative data"—specifically, scraping job boards to track headcount growth at private tech companies and monitoring retail foot traffic data through public web portals. This automated analysis reduced their research time from weeks to hours, allowing them to make investment decisions faster than their larger competitors.
Regulatory compliance was a major hurdle in this project. We ensured that all data collection was strictly limited to publicly available information and that no protected data was ever touched. By building a transparent and auditable scraping trail, we helped the firm maintain compliance while still gaining a massive informational edge. The client reported a significant increase in satisfaction among their own investors, who valued the data-driven approach to market intelligence.
Technical Challenges and Solutions
While the benefits are clear, web scraping is not without its hurdles. The web is a chaotic environment, and websites are constantly changing. A scraper that works perfectly today might break tomorrow because a developer changed a single div tag. Managing large-scale extraction projects requires a robust "self-healing" architecture that can detect these changes and alert the engineering team immediately.
Anti-bot detection is the other major challenge. As scraping becomes more common, websites are investing more in "bot management" solutions like Cloudflare or Akamai. Bypassing these requires a constant game of cat-and-mouse, utilizing advanced techniques that go far beyond simple IP rotation. At Botomation, we stay ahead of this curve by constantly updating our browser fingerprinting and proxy management strategies.
Anti-Bot Bypass Techniques
The most sophisticated anti-bot systems look at more than just your IP address. They examine your "browser fingerprint," which includes your screen resolution, installed fonts, and even the way your browser renders specific graphics. To bypass this, we use headless browser management tools that can spoof these fingerprints perfectly. We also cycle through thousands of residential proxies, which make our traffic appear to come from real home internet connections rather than a data center.
Timing is another crucial factor. If a bot visits the same 500 pages in the exact same order every hour, it is easy to detect. We implement "jitter" and randomized navigation paths to simulate natural human browsing behavior. We also use CAPTCHA-solving services that utilize a mix of AI and human workers to solve challenges when they do appear. This multi-layered approach ensures that our data collection remains uninterrupted, even against the most aggressive defenses.
Data Quality Assurance
Scraped data is often "noisy." It can contain HTML artifacts, inconsistent formatting, or missing values. To ensure data quality, we implement a series of automated validation checks. For example, if a price scraper suddenly reports a price of $0.00 for a product that usually costs $500.00, the system flags this as a potential error and prevents it from entering the main database. This "sanity checking" is vital for maintaining the trust of the end-users.
Cross-referencing data from multiple sources is another way we ensure accuracy. If three different websites report the same price for a competitor's product, we can be highly confident in that data point. If there is a discrepancy, our system can trigger a deeper analysis to determine the most likely truth. By treating data quality as a first-class engineering problem, we ensure that the intelligence we provide is not just fast, but also flawlessly accurate.
How to Set Up Your First Competitor Intelligence Scraper
If you are looking to move from manual research to automation, follow this basic framework to get started. While this is a simplified version of the enterprise solutions we provide at Botomation, it provides a solid foundation for understanding the process.
Step 1: Identify Your Targets and Data Points
Begin by listing the top 5 competitors you need to monitor. For each one, identify exactly which pages hold the most value (e.g., the /pricing page or the /blog for content trends). List the specific data points you need: product name, current price, stock status, and any discount labels.
Step 2: Inspect the Site Structure
Open your competitor's website in a browser, right-click on the data you want, and select "Inspect." Look for unique IDs or Classes in the HTML. For example, a price might be contained in a <span class=\"product-price\">. These are the "selectors" your scraper will use to find the information.
Step 3: Choose Your Environment
For a beginner, Python with the Requests and BeautifulSoup libraries is the easiest way to start. If the site uses a lot of JavaScript, you will need Playwright. Set up a local development environment and write a script that fetches the page and prints the specific selectors you identified in Step 2.
Step 4: Implement Basic Proxy Rotation
Do not scrape from your own IP address. Even a simple service like a rotating proxy provider will help you avoid getting blocked during the testing phase. Ensure you are respecting the site's robots.txt and not hitting their servers too hard.
Step 5: Schedule and Store
Once your script works, use a "cron job" or a cloud scheduler to run it at regular intervals (e.g., every morning at 8:00 AM). Direct the output into a CSV file or a simple Google Sheet. This will give you your first time-series dataset of competitor movements.
Frequently Asked Questions
Is web scraping legal for competitor intelligence?
Yes, scraping publicly available data is generally legal in most jurisdictions, including the US and EU. However, it must be done without violating the Computer Fraud and Abuse Act (CFAA) or bypassing password-protected portals. It is also essential to avoid causing technical harm to the target website through excessive traffic.
How often should I scrape my competitors?
The frequency depends on your industry. E-commerce companies often scrape hourly to keep up with dynamic pricing. In contrast, B2B service providers might only need to scrape weekly or monthly to track major feature updates or blog posts. Our team at Botomation helps you determine the optimal frequency to balance data freshness with operational costs.
Can websites block my scraping efforts?
Yes, many websites use anti-bot technology to prevent scraping. This can range from simple IP blocking to complex behavioral analysis. Bypassing these blocks requires sophisticated techniques like proxy rotation, browser fingerprinting, and human-like interaction patterns. This is why many companies choose to partner with an agency like Botomation rather than maintaining their own scrapers.
What is the difference between web scraping and web crawling?
While the terms are often used interchangeably, they differ slightly. Web crawling is the process of indexing an entire website (like Google does) to understand its structure. Web scraping is the targeted extraction of specific data points from those pages. For competitor intelligence, scraping is the primary tool used.
The competitive landscape of 2026 does not favor the slow or the uninformed. As we have explored, web scraping for competitor intelligence is the most effective way to gain a real-time, data-driven understanding of your market. The transition from manual research to automated, high-integrity data pipelines is the single biggest advantage a growth-focused company can implement today. By capturing pricing shifts, product changes, and market trends as they happen, you empower your sales and marketing teams to act with precision.
Success in this field requires more than just a script; it requires a strategic partner who understands the technical, legal, and business nuances of data extraction. At Botomation, we specialize in building these custom intelligence engines for B2B sales teams and agencies who are tired of manual research and stale lead lists. We do not just give you data; we give you a competitive edge that works while you sleep.
Ready to automate your growth? Stop losing money to faster competitors and start making data-driven decisions today. Book a call below to see how our team can build your custom market intelligence engine.
Get Started
Book a FREE Consultation Right NOW!
Schedule a Call with Our Team To Make Your Business More Efficient with AI Instantly.
Read More

Web Scraping for Competitor Intelligence - 2026 Guide
Master web scraping for competitor intelligence. Automate pricing monitoring and market trends to boost lead generation and B2B sales growth in 2026.

Extract Competitor Pricing Data with Web Scraping | 2026
Learn how WhatsApp AI slashes support costs for e-commerce & SaaS. Proven strategies to boost sales, recover carts, and scale 24/7 service.